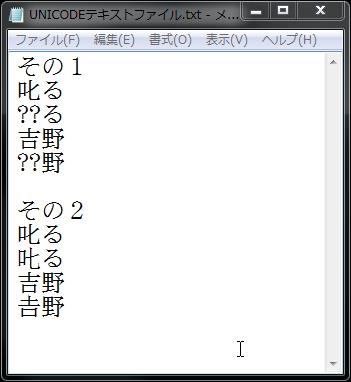
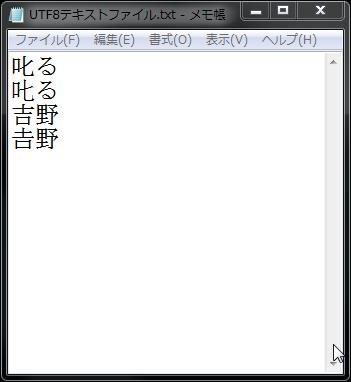
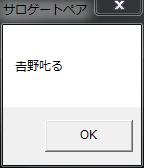
開発担当も不在となり、開発中止となったPeggyシリーズですが、2014年7月31日(木)をもってダウンロードページも閉鎖するようです。
Peggy に興味がない方も、MocaScriptはコマンドライン版が単体で使えるので、入手しておくと面白いかも。
http://www.anchorsystems.jp/anchor/ashp/moca/mocaindex.html
http://www.anchorsystems.jp/anchor/cgi/as_download.cgi
MocaScriptページのコマンドライン版の入門ガイドとリファレンスのページをコピーしておくと、使い方も分かります。
無くなってしまうのは残念です。